The Beer Mile: Down to 34 by 35
When I was a student at the University of South Carolina, someone mentioned to me that a mutual friend of ours had set the South Carolina record in the beer mile. "What's a beer mile?" I asked.
It turns out that a beer mile is a chess boxing-like hybrid sport, simultaneously testing one's fleet footedness and ones beer chugging ability. The event begins with the competitor opening a 12oz (or more) can/bottle of 5% ABV (or more) beer in the staging zone. The brave soul then chugs the beer as quickly as possible before beginning a quarter-mile run. At the end of the quarter mile, the competitor opens a second beer and repeats the performance, and likewise for a third and fourth lap. Vomiting before the completion of the fourth lap results in a penalty lap, though no penalty beer. The complete rules fill in the other details.
My friend, the apparent SC state champion beer miler, seemed uniquely suited to the event: he was both an NCAA 1600m runner and a heavy drinker. Perfect for the event. Word on the street was that he had run it in some mind-boggling time like 6:30 or something. Really crazy, but not my cup of tea. I forgot about the beer mile.
Last year, my interest in the beer mile was renewed when someone told me about a race in which you eat an entire French dinner, with a course after each leg of the race [citation needed? can't seem to find the race on the internet]. I remembered the beer mile, and put the event in my 35 by 35 list, ensuring its completion (or at least, that I wouldn't forget it about it). It wasn't until six months ago that I got serious about it. I floated the idea to my friend Jacob who, like my college beer mile champion friend, was both exceptional drinker and runner. He loved the idea, and we ended up talking about it often. He found this insane video of what appears to be the world-record beer mile, and we were inspired:
We started talking strategy. Where and when could we do the run such that we wouldn't get hassled under Virginia's archaic public drinking laws? The track was the obvious choice, but when? The track is almost always populated, so we never came to a consensus. Instead, we both found ourselves in the Myrtle Beach area over the Fourth of July and took it as a sign.
The Sunday after the Fourth, Jacob met me at my parents place. We originally intended to run on the beach, but the combination of high tide and lots of people pushed us onto the road instead. Our enthusiasm was infectious, and my family and some friends came out to cheer us on (actually, laugh at us) and time our attempt. My buddy Geoff also decided to run. We lined up and GPS'ed a 0.25mi course. We acquired a case of the classic, Bud Diesel, like our hero in the video above, set up our cans, and prepared ourselves mentally and physically. Even at 9AM it was crazy hot, and we were sweating before we started. Here's us lined up to go:

Someone counts us down and fired the starting pistol. We grab our first beer and chugged it down. The beer is pretty warm, as it had been sitting out on the driveway while we did all our preparation, and it foams over the top of the can. Not a good sign. Regardless, we all did pretty well on the first lap. We get back, pop the second top and start drinking. The second one is much harder than the first. By this point, Jacob is already in a commanding lead, with Geoff and I roughly neck and neck. The second run felt pretty awful, and as I opened the third beer I announced that this was the worst I had ever felt from any exercise ever. Also that I felt like a giant bubble. I was having trouble burping to get rid of the carbon dioxide in my stomach, and it was not going well. I slogged slowly through the third beer. I thought briefly about giving up, throwing in the towel, but I reminded myself that the list item was complete a beer mile, not attempt a beer mile. Right before I finished my third beer, Jacob crossed the finish line on his final lap, and the support crew announced his time: 10:05. He slowed down and immediate yakked up a bunch of foamy lager.
I took off running while he was still cleansing himself of impurities. I pushed on, barely running with a belly full of foam sloshing around. I hear everyone yelling, and here comes Jacob passing me on what turned out to be his irrelevant penalty lap - you only have to run a penalty if you puke before the race is over. I finish my third lap. I open the fourth beer. I stare at it. I drink some. I feel terrible. I am sweaty, my stomach feels awful, its 9:10 in the morning, the sun is beating down. Geoff is beating me. Somehow, we both finish our beers and take off running, Geoff a few steps ahead. I see him slow and bend over, and he loses it, booting in the middle of the road. I realize I am going to do the same and turn into some bushes.
I puke and it's nothing but foam, two big throatfuls. It all comes out in the second one, and like magic I feel totally fine. This is seriously the highest gain in personal wellbeing I have ever experienced. Plodding ahead, I was completely overwhelmed by how terrible I felt; after my moment in the bushes, I felt... well, maybe not quite 100%, but super good. I take off sprinting, hit the turn, pass Geoff. I am actually running for the first time since the first lap! I cross the line and immediately turn for my penalty lap. I am really running hard, and I finally finish the race! I don't even feel that sick, though I am totally out of breath after sprinting a half mile. My dad jokingly hangs a leftover race medallion from a previous half marathon around my neck. Here's me after the race:

My penalty lap time turned out to be 1:38, which isn't really that bad for the last of five quarter miles. Here are my splits:

Each split includes the preceding beer as well, so beer 1 + lap 1 took me 2:07. As you can see, the third lap (really the third beer) was the most brutal by a wide margin. As a bonus, Geoff was wearing his Fitbit, so we also have all kinds of cool stats from his run. Here's the output:
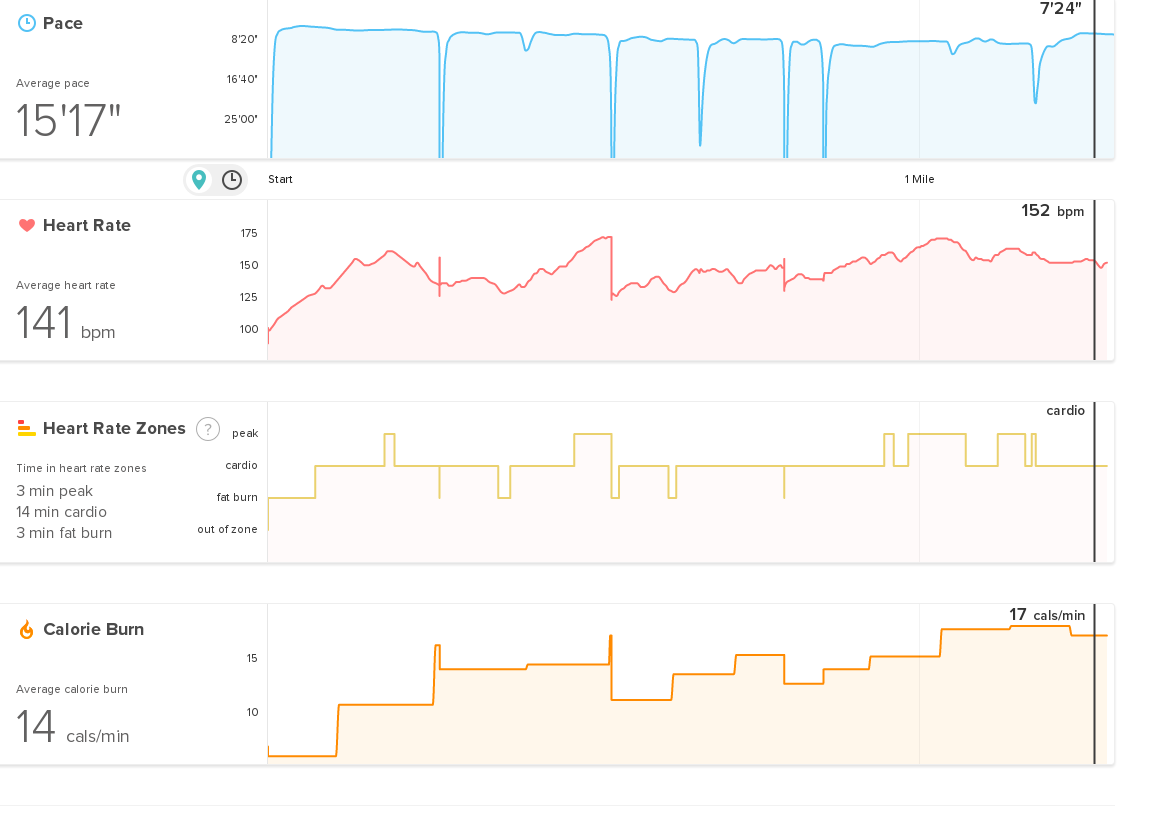
So there we have it. My first beer mile, and my first item off of the 35-by-35 list. Hilarious, gross, difficult, incredibly painful, and lots of fun. No regrets.
 becomes
becomes

 becomes
becomes

 becomes
becomes

The Beer Mile: Down to 34 by 35